[Domain Adaptation] Image to Image Translation for Domain Adaptation
Abstarct
본논문에서 제시하는 방법을 이용하면 Source domain에서 학습한 신경망이 target domain에서 ground truth가 없음에도 불구하고 학습이 가능하도록 할 수 있다. 이를 위해서는 backbone encoder network에서 나온 feature를 정규화하기 위한 extra network와 losses를 추가해주어야 한다. 이를 위해 우리는 최근(2018년) 제안된 “unpaired image to image translation framework”의 색다른 사용법을 제시할 것이다. 이때 추출된 feature는 두 도메인의 이미지를 재구성할 수 있어야 하며 두 도메인의 이미지에서 추출된 기능의 분포를 구분할 수 없어야 한다. 우리는 분류 작업시 MNIST, USPS 및 SVHN 데이터 셋트와 Amazon, Webcam 및 DSLR Office 데이터 세트 간, 그리고 세분화 작업을 위해 GTA5 및 Cityscapes 데이터 세트간의 domain adaptation방법을 적용하였다. 그리고 위와 같은 데이터 세트에서 SOTA를 찍었다.
Introduction
우리는 신경망을 학습하기 위하여 풍부한 양의 데이터 셋을 필요로 한다. 그러나 이러한 데이터셋을 모으는데는 많은 비용이 소모된다. 따라서 라벨링된 데이터를 갖는 도메인으로부터 라벨링 되지 않거나 약간만 라벨링이 된 target domain으로 학습된 지식을 전달할 필요가 있다. 그리고 이러한 knowledge transfer를 domain shift라 하는데 이는 source domain과 target domain의 분포의 차이를 나타낸다.
자율주행에서의 객체 인식 같은 경우는 segmentation network를 훈련시키기 위하여 각 장면에 대하여 semantic하고 instance-wise한 픽셀 단위의 라벨링이 필요하며 이는 비용이 많이 들고 획득하는데 많은 시간이 소요된다. 따라서 대부분의 경우 human annotation을 피하기 위해 ground truth annotations를 쉽게 사용할 수 있는 realistic한 시나리오 설계에 중점을 둔다. 실제로 Synthia, Virtual KITTI, GTA5데이터셋들은 이러한 시뮬레이션의 예이고 실제로 픽셀 수준의 semantic annotation과 함께 생성된 수많은 운전 장면을 포함한다. 그러나 실제로 이러한 데이터를 기반으로 CNN을 훈련하고 cityscapes dataset과 같은 실제 이미지에 적용하면 domain간의 차이로 인하여 성능이 크게 저하된다. 그리고 이를 domain shift problem이라한다.
따라서 domain adaptation 기술은 source data distribution에서 target distribution으로의 mapping을 찾아서 domain shift problem을 해결하는 것을 목표로 한다. 혹은 두 도메인의 distribution이 align될 수 있는 공유 도메인에 mapping하는 방법도 있다. 그러나 이러한 mapping은 하나만 존재하는 것이 아니며 source 및 target distribution을 align하는 많은 mapping들이 존재한다. 따라서 mapping 공간을 좁힐 필요가 있고 이를 위해서는 다양한 constrain이 필요로 한다. 최근 domain adaptation 기술은 deep neural network를 통해 이러한 mapping을 매개변수화 하고 학습한다. 본 논문에서는 unsupervised domain adaptation을 위한 통일되고 포괄적이며 체계적인 framework를 제안할 것이며 이는 target domain에서 training label이 유효하지 못한 많은 image understanding 및 sensing 작업에 광범위하게 적용할 수 있다. 또한 domain adaptation을 위한 기존의 많은 방법이 특정한 frame work에서만 작동하는 것을 보여준다.
최근의(2018년) domain adaptation 방법 간에는 상당한 차이가 있지만 공통적이고 통일된 주제가 존재한다. 우리는 성공적인 unsupervised domain adaptation을 달성하기 위하여 다음 3가지 주요 속성을 필요로 한다.
- Domain agnostic feature extraction (도메인 불가지론적 특징 추출)
- 두 도메인에서 추출된 지형 지물의 분포가 구별할 수 없는 수준이어야 한다.
- Domain specific reconstruction
- Feature를 source및 target domain으로 다시 디코딩 할 수 있어야 한다.
- Cycle consistency
- Unpaired 된 소스 및 대상 도메인에 대해 cycle consistency가 필요하므로 분포가 단일 모드로 축소되지는 않는지 확인해야 한다.
다음 그림은 본 논문의 framework에 대한 개괄적인 개요를 제공한다.
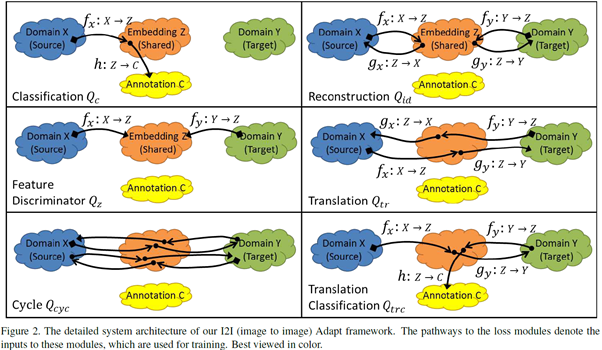
위의 3가지 속성 간의 상호 작용을 통해 framework는 source domain에서 동시에 학습하고 target domain에 적응할 수 있다. 이러한 모든 다른 구성요소를 단일 통합 framework로 결합하여 실험 결과뿐 아니라 깔끔한 이론적 설명을 제공하는 domain knowledge transfer를 위한 체계적인 frame work를 구축한다.
우리는 synthetic image(비디오 게임으로부터 나온 이미지)에서 실제 이미지로의 segmentation adaptation과 three digit dataset의 classifier adaptation을 위해 제안된 framework의 우수한 성능을 보여줄 것이다. 또한 많은 SOTA 방법을 제안된 framework의 특수한 사례로 볼 수 있음을 보여준다.
Related Work
Dataset bias problem(데이터셋 편향 문제)로 알려진 domain shift 문제를 해결하는 최근(2018)의 많은 연구들이 있었다. 최근 작업의 대부분은 deep convolution architecture를 사용하여 source 및 target domain을 domain aligned된 공유 공간에 매핑하는 방식을 사용하였다. 이러한 방법들은 architecture와 loss function에 따라 크게 다르다. Source domain과 target domain 사이에 MMD(Maximum Mean Discrepancy)를 사용하는 경우도 있었고 다른 GAN을 사용하는 경우도 있었다.
- Fcns in the wild : Pixel-level adversarial and constraint-based adaptation
- Domain adversarial training에 fully convolutional network를 사용하여 source domain과 target domain에 대한 domain agnostic features(도메인 불가지론적 특징)을 획득하는 한편, shared space가 source domain에 대해 discriminative함을 제안하였다. 따라서 source 및 target 도메인에서 shared space로의 mapping을 학습하고(그림2의 fx밑 fy ) shared space에서 annotation으로 mapping을 학습함으로서(그림 2의 h) 이들 접근 방식은 학습된 classifier를 효과적으로 활성화 한다. 이는 두 domain모두에 적용 가능하다.
- Deep reconstruction-classification networks for unsupervised domain adaptation.
- 1과 유사한 접근 방식을 사용하지만 embedding은 반드시 dcodable 해야 한다는 constrain을 가지고 embedding space에서 target domain으로의 mapping을 학습한다.(그림 2의 gy)
언급된 논문에서 종합적으로 언급되는 것은 다음과 같다.
Shared space는 반드시 source domain으로부터 discriminative embedding이어야 한다.
Embedding은 반드시 도메인과 불가지론적이여야 한다. 그러므로 target image와 embedding source사이의 분포의 유사성이 최대가 되어야 한다.
고전적 loss와는 반대로 adversarial training은 train된 mapping의 품질을 크게 향상시킬 수 있다.
Source domain과 target domain이 대부분 pairing 되어 있지 않으므로 mapping을 학습할 때 가능한 mapping의 공간을 줄이고 품질을 보장하기 위하여 cycle consistency가 필요하다.
Unsupervised domain adaptation을 위한 our proposed method는 위에서 언급한 부분들을 domain adaptation image-to-image translation problem을 동시에 해결하는 일반적인 frame work로 통합한다.
최근 deep domain adaptation을 위한 unifying하고 general한 framework를 향한 최근 논문들이 있었다. 일례로 Adversarial discriminative domain adaptation이 있다. 여기서는 deep domain adaptation system에 대한 3가지 설계를 보였다.
Generative or discriminative기반 사용여부
f~x~와 f~y~간에 mapping 매개 변수 공유 여부 및 적대적 훈련의 선택
embedding이 domain에 구애 받지 않는 경우
위 3가지 경우에 대하여 모델링 이미지분포가 엄격히 맆요하지 않을 수 있음을 관찰하였습니다. 우리와 매우 유사한 아이디어가 “Cycle-consistent adversarial domain adaptation”이라는 이름으로 동시에 출판되었다.
Method
Domain adaptation은 few-shot learning이나 semi-supervised learning으로도 확장 가능하다. Target domain의 label이 없는 경우 일반적인 학습 방법은 source domain에서 classifier를 학습하고 해당 domain의 distribution이 target domain과 일치하는 방식으로 조정하는 방법을 사용한다.
여기서 가장 중요한 아이디어는 source 및 target domain의 공동 latent space를 찾는 것이다. 여기서 representation은 domain agnostic해야 한다. 예를 들어 X는 맑은 날 운전하는 장면, Y는 비가 오는 날 운전하는 장면이라 가정하자. 이 때 날씨는 source 및 target domain의 특성이지만 annotation에 영향을 미쳐서는 안 된다. 따라서 우리는 structured noise와 같은 특성을 처리하여 이러한 변동에 영향을 미치지 않는 latent space Z를 찾아야 한다. 즉 domain Z는 domain에 의존적이지 않아야 한다. 그렇다면 이러한 latent space Z를 어떻게 찾는지에 관하여 설명하겠다.
우선 source domain 및 target domain에서 latent space로의 mapping을 각각 (f~x~ : X -> Z), (f~y~ : Y -> Z)로 정의하자. framework에서 이러한 mapping은 CNN에 의하여 매개 변수화 된다. Lattent space z ∈ Z의 member는 image level task의 경우 고차원 벡터이거나 픽셀 레벨 task의 경우 feature map이다. 또한 (h: Z->C)를 latent space를 labels/annotations(예 : 그림 2의 classifier module)에 mapping하는 classifier라 하자. Source class X에 대한 annotation이 있다면 h(f~x~(x~i~))를 시행하기 위한 supervised loss를 정의할 수 있다.
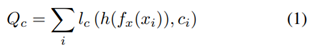
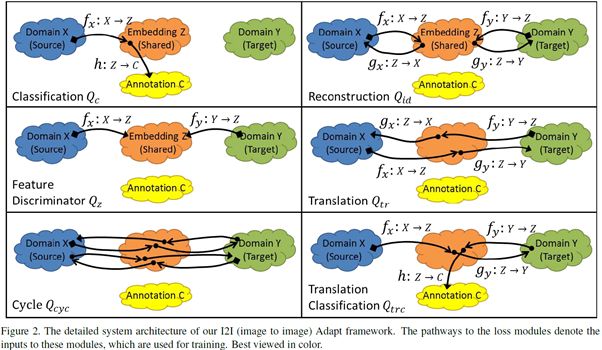
위의 loss function을 최소화하면 supervised learning의 표준 접근 방식이 생겨 domain adaptation과는 관련이 없다. 이러한 접근 법은 source domain의 이미지에서 잘 수행되는 방법은 맞지만 target domain의 이미지에서 제대로 수행되지 않는다. 왜냐면 domain Z가 source domain에 편향되어 있고 target domain의 structured noise가 classifier인 h를 혼동시키기 때문이다. 따라서 이러한 혼동을 피하기 위해 latent space Z는 domain에 구애 받지 않아야 한다. 이러한 latent space를 달성하기 위해 latent space를 정규화하고 결과적으로 강력한 h를 만들 수 있도록 다양한 보조 네트워크(auxiliary network) 및 loss를 도입해야 한다. 보조 네트워크와 loss pathway는 그림 2에 나와있다. 이제 다음으로는 regularization loss의 개별 구성요소를 설명하겠다.
우선 Z는 target 및 source 이미지의 핵심 정보를 보존하고 구조화된 noise만 제거하기 위하여 필요하다. Latent space에 이러한 constrain을 가하기 위해 먼저 latent space의 feafe를 가져오는 decoder인 gx : ZàX 및 gy : Z à Y를 정의한다. 만일 Z가 도메인의 핵심 정보를 유지하고 구조화된 noise를 버린다면 decoder는 구조화된 noise를 다시 추가하고 latent space Z에서의 표현으로부터 각 이미지를 재구성할 수 있어야 한다. 즉 a = g(f(a))를 만족해야 한다. 이를 손실함수로 쓰면 다음과 같다.
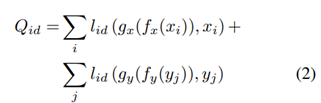
누차 말하지만 latent space Z는 domain에 구애받아서는 안된다. 즉 source 및 target domain의 specific information을 포함해서는 안된다는 것이다. 이를 위해 우리는 discriminator dz : Z à{cx, cy}가 latent space z ∈ Z가 X에서 생성 됬는지 Y에서 생성 됬는지를 구분하고자 할 것이다. 이를 공식화 하면 다음과 같다.
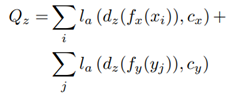
따라서 generator는 이 loss를 극대화 하고자 할 것이고 discriminator는 이 loss를 최소화 하고자 할 것이다.
fx, fy, gx, gy의 매핑이 일관되게 보장하기 위해 translation adversarial loss를 정의할 것이다. Source domain의 이미지가 먼저 latent space로 인코딩 된 후 source domain으로 decoding되 가짜 이미지가 생성된다. 그 후 이미지가 가짜 인지 진짜인지 판별하는 dx : X à {cx, cy}및 dy : Y à {cx, cy}를 정의한다. 이를 손실함수로 쓰면 다음과 같다.
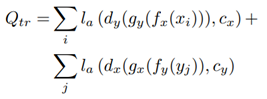
source domain과 target domain의 image사이의 대응 관계가 없기 때문에 두 domain에서 의미적으로 유사한 이미지가 latent space에서 서로 가까운 곳에 투사되도록 해야한다. 이를 보장하기 위하여 translation loss인 g~x~(f~y~(y~j~)) 또는 g~y~(f~x~(x~i~))에서 생성된 fake image가 latent space로 다시 인코딩 된 후 decoding 되는 cycle consistency loss를 정의한다. 이 때 entire cycle은 identity mapping과 동일해야 한다.
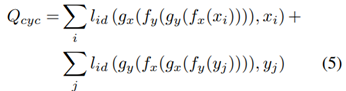
translation이 동일한 의미를 유지하도록 translation을 constrain하고 target encoder가 target domain과 유사한 이미지에 대한 supervision으로 훈련될 수 있도록 하기 위해 source에서 target translation과 original source label사이의 classification loss도 정의한다.
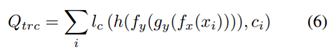
이제 최종적으로 위의 5개의 loss를 합하여 general loss를 다음과 같이 정의한다.
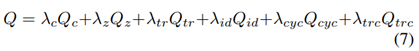
Domain adaptation을 위한 다양한 방법들(이전까지의)은 우리들의 framework의 포함됩니다. 표 1에는 이러한 다양한 방법들(이전까지의)을 recover하기 위해 포함해야 할 hyperparameters들이 요약되어 있다.

Experiments
다음의 조건을 가지고 실험하였다.
Optimazer : Adam
lr : 0.0002
Betas[2] : 0.5, 0.999
Discriminator와 encoder를 번갈아 학습시킴
Encoder의 가중치를 공유
Decoder는 처음 몇 레이어의 가중치를 공유
Discriminator Qz의 loss는 target image generator로만 역전파됨(encoder가 target image를 source image와 동일한 분포에 mapping되는 것이 좋으므로, not vice versa)
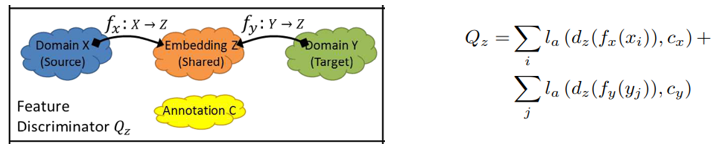
Translation classification loss는 seconde encoder와 classifier(fy , h)로만 역전파 된다. 이는 translate된 image에서 class정보를 숨겨 gy의 부정행위를 막는다
Experiments - MNIST, USPS, SVHN

Feature extranctor는 이전 방법들과의 비교를 위하여 LeNet을 사용했다(Modified version). 본 논문의 decoder는 3개의 transposed convolutional layer로 구성되고 image discriminator(Q~tr~)는 3개의 convolution layer로 구성되며 feature discriminator(Q~z~)는 3개의 fully connected layer로 구성된다. 또한 MNIST 및 USPS의 모든 이미지는 32*32로 bilinearly unsampled되었고 SVHN의 이미지는 gray scale시켰다. 그리고 random translation이나 rotation과 같은 데이터 보강 기법도 사용하였다. 하이퍼 파라미터로는 λ~c~ = 1.0, λ~z~ = 0.05, λ~id~ = 0.1, λ~tr~ = 0.02, λ~cyc~ = 0.1, λ~trc~ = 0.1 을 사용하였다. 그리고 이들을 이전의 9개의 works와 비교하였다.
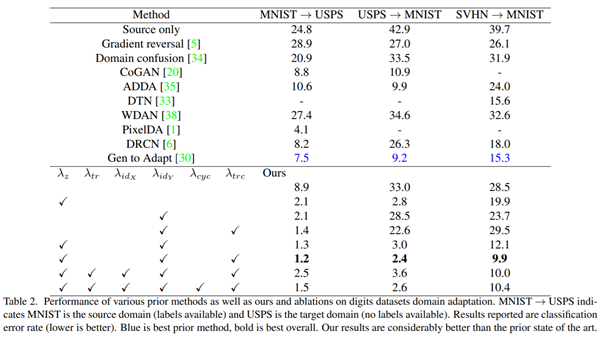
우리의 방법이 굉장히 높은 정확도를 보임을 알 수 있다. 그리고 각 loss terms이 전체 성능에 얼마나 많은 영향을 미치는지 분석하기 위해 몇 개를 제거하며 실험하였다. 먼저 domain adaptation을 하지 않은 경우(맨 아래 행)도 이전 방법보다는 나은데 이는 단순히 데이터의 증가 때문이다. 그리고 이 실험을 통하여 λ~z~와 λ~idy~가 성능향상에 큰 역할을 할 수 있음을 알 수있었고 여기에 λ~trc~와 함께 사용하면 더 좋은 결과를 얻을 수 있었다. 이러한 특징은 가장 어려운 문제인 SVHN에서 MNIST로 갈 때 더 명백히 보인다. 그리고 위와 같은 dataset에서 방금 언급한 loss term을 제외하고는 도움이 되지 않았다.
다음 그림은 adaptation 없이 image to image loss만 사용하고 전체 모델로 학습을 했을 때의 source 및 target domain에서 extract된 feature의 TSNE embedding을 보여준다.

Adaptation이 없으면 source 및 target image가 feature space에서 clustering되지만 distribution이 겹치지는 않으므로 target domain에서 distribution이 실패하는 것을 알 수 있다.
Image to image translation만으로는 network가 source 및 target distribution을 feature space의 다른 영역으로 mapping하는 것을 학슬 할 때 강제적으로 두 도메인의 distribution을 overlap하기에는 부족하기 때문이다.(즉 network가 두 도메인을 overlap해야 한다는 것을 배우지 못함)
Experiments – Office dataset

Office dataset은 위와 같이 Amazon, Webcam, DSLR의 3가지 도메인에 있는 31개의 클래스를 가진 dataset이다. 본 논문에서 제안하는 방법은 6가지의 작업중 4가지 조합에서 SOTA를 찍었다. 우리가 SOTA를 찍지 못한 2가지 작업은 source domain의 training data가 매우 적은 상황에서 대규모 domain shift를 수행하는 것이다.
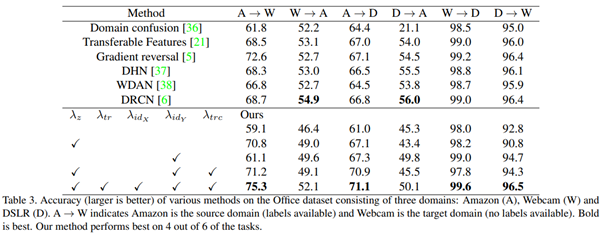
이미지는 256x256으로 다운 샘플링 된 다음 224x244 크기의 임의 자르기가 추출됩니다. 최종 분류 계층은 전체 평균 풀링 후에 적용됩니다. 우리의 디코더는 5 개의 보폭 2 개의 전이 된 컨볼 루션 레이어로 구성됩니다. 이미지 판별 기는 4 개의 보폭 2 개의 컨볼 루션 레이어로 구성됩니다. 특징 판별 기는 3 개의 1x1 컨볼 루션과 그 뒤에 글로벌 평균 풀링으로 구성됩니다. 하이퍼 파라미터는 λ~c~ = 1.0, λ~z~ = 0.1, λ~tr~ = 0.005, λ~id~ = 0.2, λ~cyc~ = 0.0, λ~trc~ = 0.1입니다.
위의 결과를 볼 때 translation loss(Q~tr~)이 도움이 된다는 것을 알 수 있습니다.
Experiments – GTA 5 to Cityscapes**
Synthetic driving data set인 GTA5와 실제 dataset인 Cityscapes 사이의 domain adaptation 방법도 설명하겠습니다. GTA 5 dataset은 Cityscapes dataset과 호환되는 19개의 class를 포함하는 1914*1052 크기의 24,966개의 밀도 높은 RGB 이미지로 구성됩니다. 그리고 Cityscapes dataset은 27개의 도시에서 2040 * 1016 크기의 5,000개의 밀도 높은 RGB 이미지가 포함되어 있습니다. (픽셀 수준의 semantic segmentation으로). 여기서 GTA5 이미지를 레이블이 지정된 source dataset으로 사용하고 Cityscapes image를 레이블이 없는 target domain으로 사용할 것입니다.
메모리 문제로 인하여 cycle consistency constraint는 포함되지 않았습니다. 그리고 마찬가지로 메모리 문제로 인하여 모든 이미지를 2배로 down sampling하여 사용하였습니다. 하지만 출력은 원래 해상도로 이중 선형으로 샘플링 된다.
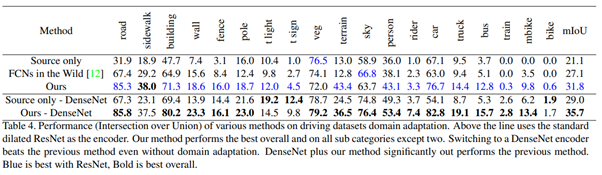
아래 그림을 보면 우리의 segmentation이 질적으로 더 깨끗하다는 것을 볼 수 있습니다. 그리고 위 표를 보면 양적으로 3을 제외한 모든 범주에서 이전까지의 방법들 보다 성능이 좋다는 것을 볼 수 있다.

Conclusion
본 논문에서는 unsupervised domain adaptation을 위한 일반적은 framework를 제시하였다. 본 논문에서의 구현은 digit classification과 semantic segmentation에 있어서 SOTA를 찍었다. DenseNet architecture와 결합하면 SOTA를 찍는다.