Label Refinery: Improving ImageNet Classification through Label Progression
해당 논문에서는 Label Refinery라는 반복 프로세스를 소개한다. 이 프로세스는 시각적 모델을 사용하여 실제 레이블을 개선하여 ImageNet의 다양한 아키텍처 전반에 걸쳐 분류 모델의 정확성과 일반화를 크게 향상시킨다.
메인 아이디어 : label 을 hard하게 주지 말고 soft하게 주자.
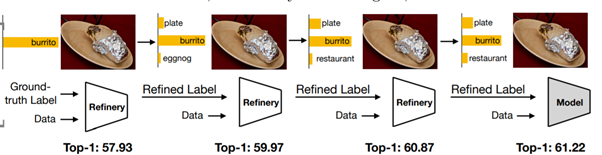
밑의 그림을 burrito라고 classification하는 것은 잘못되었다.
Plate도 같이 찍혀 있으므로 label을 다음과 같이 soft하게 주는 것이 올바르다. 왜냐하면 하나의 이미지안에 2가지 클래스가 있는 경우도 있기 때문이다(또한, 1가지의 클래스만 있다 하여도, 개체에 따라 “강아지를 닮은 고양이”와 같은 것들이 있기에 soft label이 유리할 것으로 추정된다). 이 때 label을 soft하게 주기 위하여 teacher-student 모델이 사용된다.
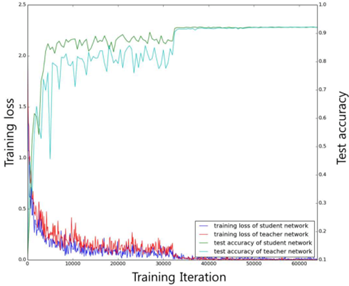
다음 그래프를 보면 student의 성능이 teacher 못지 않는 성능일 보임을 알 수 있다.
수식은 다음과 같은 KL-divergence를 사용한다. \[D_{KL} = (P\|Q) = \sum_i P(i) \log{P(i)\over Q(i)}\]
Student model인 $ Q(i) $ 가 teacher model 인 $ P(i) $ 에 가까워질수록 KL-divergence는 작아진다.
이를 본 논문에 맞게 다시 쓰면 아래 식과 같다. 여기서 빨간 박스친 부분은 student model로부터 독립적이므로 식을 더 간단히 쓸 수 있다.
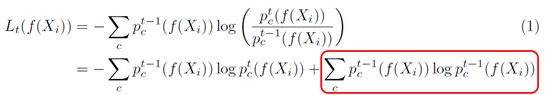
따라서 최종 식은 다음과 같이 나온다.
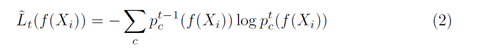
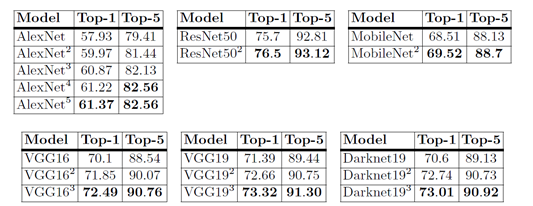
다음 결과를 보면 teacher-student 모델을 거칠수록 점차 accuracy가 올라가는 것을 볼 수 있다.