MultiPath Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction
Multipath 논문 정리. 논문 링크
Abstract
실제 환경에서 인간의 행동을 예측하는 무척이나 어렵다. 논문의 저자는 single MAP trajectory prediction을 넘어 미래의 정확한 확률 분포를 얻는 것에 관심을 두었다(사람이 미래에 오른쪽으로 갈지 왼쪽으로 갈지 정확히 맞추는 것은 불가능하다. 따라서 확률 분포를 모델링하겠다.).
따라서 본 논문에서는 궤적 분포 모드(modes of the trajectory distribution)에 해당하는 고정된 미래 상태의 sequence 앵커 세트(fixed set of future state-sequence anchors)를 사용하는 multipath를 제시한다. 추론시 우리 모델은 앵커에 대한 이산 분포를 예측하고 각 앵커에 대해 불확실성과 함께 앵커 way-point에서 오프셋을 회귀하여 각 시간 단계에서 가우스 혼합을 산출한다.
즉 쉽게 말하면 오른쪽으로 갈 확률, 왼쪽으로 갈 확률, 직진할 확률은 우선 모델링하고 이를 앵커로 삼아 만약 왼쪽으로 가게된다면 궤적의 분포가 어떻게 나올지를 보다 정확히 모델링하겠다(아래 그림은 대충 느낌만 파악하자. 더 자세한건 밑에서 설명하겠다).
Introduction
자율주행에서 중요한 과업은 동일한 지역에 있는 다른 agent(e.g. 보행자, 상대방 차량등)의 행동을 예측하는 것이다(양보를 할지 안 할지). 이러한 미래 예측은 다음 그림에 묘사된 바와 같이 도로 정보(차선 연결, 정지선), 신호등 정보, 다른 agent의 과거 경로 등과 같은 정적 및 동적 세계의 이해를 필요로 한다.
미래 예측 시 고려해야할 중요한 점은 미래 예측은 stochastic하다는 것이다(다른 사람들의 행동을 정확히 예측하는 것은 불가능하기 때문). 따라서 여러 결과와 가능성을 고려해야 한다.
본 논문에서는 다음 2가지 조건을 만족하는 네트워크를 찾는다.
- 가능한 결과의 공간을 포괄하는 간결한 이산 궤적(discrete trajectories)의 집합
- 모든 궤적의 가능성에 대한 폐쇄형 평가(closed-form evaluation)
이 두가지 속성을 모두 만족시키기는 굉장히 어렵다. Diversity와 coverage를 모두 달성하려는 모델은 종종 훈련중에 mode collapse를 격을뿐 아니라 가능한 궤적 역시 시간이 지남에 따라 기하 급수적으로 증가하기 때문에 확률적 추론이 어렵다.
본 논문의 multipath 모델은 아래 방법을 통해 이와 같은 문제들을 해결 가능하게 한다.
intent uncertainty(agent가 왼쪽으로 갈지, 오른쪽으로 갈지 모른다)은 agent가 수행하려는 작업의 불확실성을 포착하고 앵커 궤적 세트에 대한 분포로 인코딩 된다.
의도가 주어지면 control uncertainty은 그것을 어떻게 달성할 수 있는지에 대한 우리의 불확실성을 나타낸다.
본 논문에서는 위의 2-step을 통해 불확실성을 계층 적으로 받아들일 수 있다.
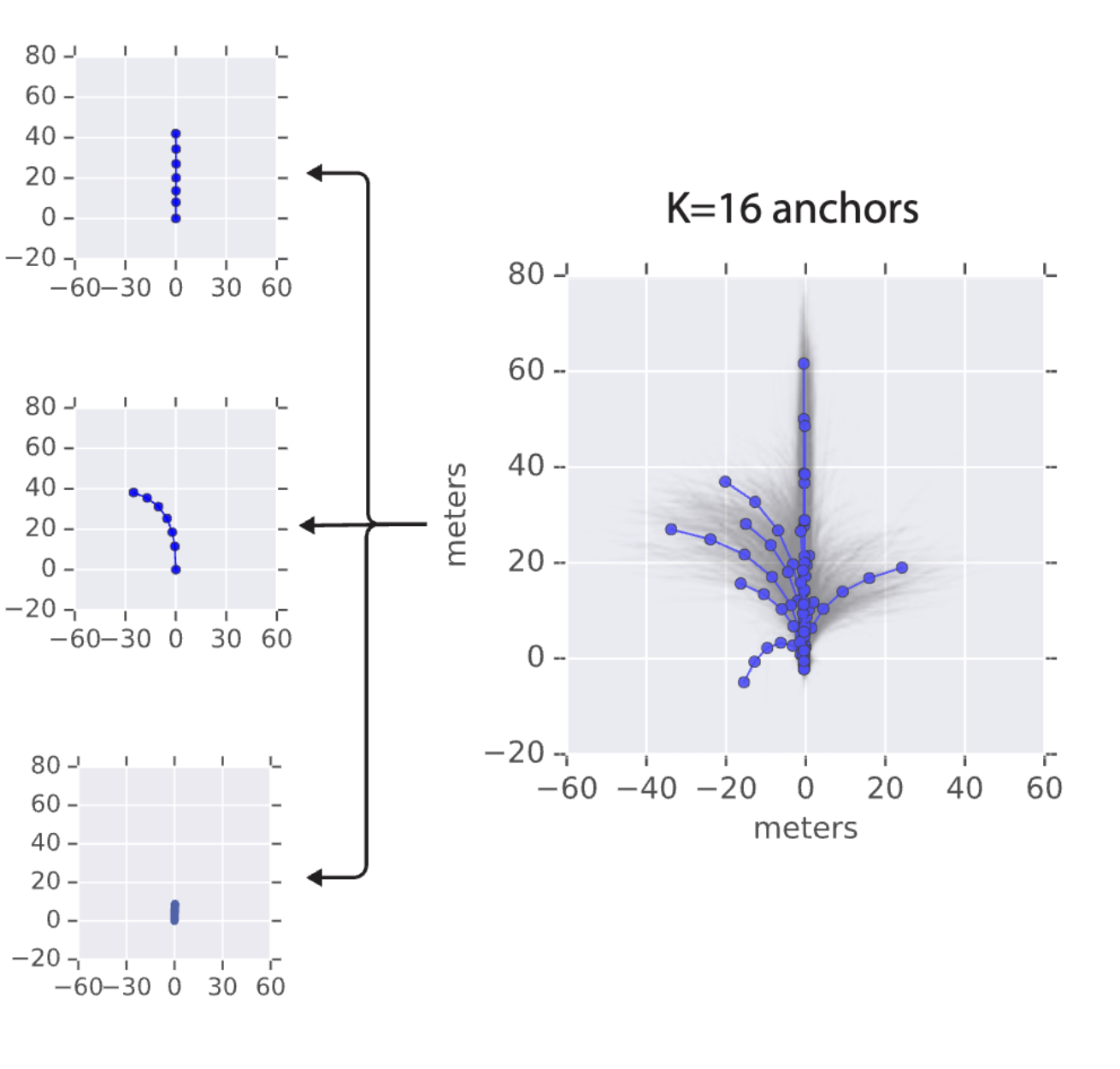
제어 불확도(control uncertainty)는 각 미래시간 단계에서 정규 분포화 되어 있고 평균이 anchor state에서 context-specific offset에 부합되도록 매개변수화 되고 관련 공분산이 unimodal aleatoric uncertainty(단봉 내재적 불확도)를 포착한다고 가정한다. 다음 그림은 도로 geometry를 고려한 제어 평균 오프셋 세분화와 시간이 지남에 따라 직관적으로 증가하는 제어 불확실성과 함께 장면 context에 따라 3가지 가능성 있는 의도가 있는 전형적인 시나리오를 보여준다.
궤적 앵커는 비지도 학습을 통해 state-sequence 공간의 training data에서 발견되는 mode이다. 이러한 앵커는 agent에 대한 대략적인 미래에 대한 템플릿을 제공하며 “차선 변경” 또는 “느린 속도”와 같은 의미 개념에 해당할 수 있다 (명확하긴 하지만 모델링에 의미 개념을 사용하지는 않음).
전체 모델은 시간이 지남에 따라 고정된 혼합 가중치(intent distribution)를 사용하여 각 시간 단계에서 가우스 혼합 모델(GMM)을 예측한다. 이러한 모수 분포 모델이 주어지면 미래 궤적의 가능성을 직접 평가할 수 있으며 각 앵커 의도의 MAP 샘플인 작고 다양한 가중치가 적용된 궤적 샘플 세트를 얻을 수 있는 간단한 방법도 있다.
본 논문의 모델은 과거 접근 방식(MAP 궤적, 생성모델을 통해 가중치가 적용되지 않는 샘플 세트)들과 대조된다. 자율 주행 차량과 같은 실제 어플리케이션과 관련하여 샘플 기반 방법에는 여러 단점이 있다.
안전에 중요한 시스템의 비결정성 근사 오류 처리 불량(보행자가 무단횡단을 할 가능성을 알기 위해 몇 개의 샘플을 그려야 하나?) 시공간 영역에 대한 기대치를 계산하는 것과 같은 관련 query에 대해 확률적 추론을 수행하는 쉬운 방법이 없다.
- 안전에 중요한 시스템의 비결정성
- 근사 오류 처리 불량(보행자가 무단횡단을 할 가능성을 알기 위해 몇 개의 샘플을 그려야 하나?)
- 시공간 영역에 대한 기대치를 계산하는 것과 같은 관련 query에 대해 확률적 추론을 수행하는 쉬운 방법이 없다.
본 논문에서는 모델이 synthetic 혹은 real 양쪽 모두에서 더 좋은 결과를 얻을 수 있음을 경험적으로 보여준다. 해당 방법은 unimodal parametric distributions을 방출하는 모델보다 더 높은 likelihood를 달성하여 실제 데이터에서 다중 앵커의 중요성을 보였다. 또한 sample-set metric에서 훨씬 적은 수의 샘플로 미래를 더 잘 설명하는 anchor 당 MAP trajectory weight set을 사용하여 샘플링 기반 방법과 비교해 보았다.
Related work Permalink
우리는 미래 궤적 분포를 예측하는 이전 접근 방식을 결정론적 모델 혹은 확률적 모델의 두가지 클래스로 광범위하게 분류한다.
결정론적 모델은 일반적으로 감독 회귀를 통해 agent 당 가장 가능성이 높은 단일 궤적을 예측한다.
확률적 모델은 학습 및 추론 중에 무작위 샘플링을 통합하여 미래의 비 결정성을 포착한다(kitani et al의 정액 움직임 예측 작업). 이를 Markov 의사 결정 과정으로 캐스팅하고 자기 중심적(egocentric)인 비디오 및 보행자에 초점을 맞춘 작업에 대한 후속 조치와 마찬가지로 1-step policy를 배운다. Sample diversity와 coverage를 장려하기 위하여 R2P2는 예측 분포와 데이터 분포 사이의 대칭 KL loss를 제안한다. 여러 연구에서는 샘플을 생성하기 위해 CVAE 및 GAN을 사용하는 방법을 탐색한다. 이러한 비 결정적 접근 방식의 한가지 단점은 더 큰 시스템에서 결과를 재현하고 분석하기 어렵게 만들 수 있다는 것이다.
본 논문과 마찬가지로 이전의 몇가지 연구는 매개변수 또는 확률적 상태 공간 점유 격자의 형태로 확률 분포를 직접 모델링하였다. 이는 매우 유연하지만 POG는 몇가지 매개변수가 아닌 분포를 설명하기 위해 상태 공간 밀집 스토리지가 필요하며 POG 시공간 볼륨에서 궤적 샘플을 추출하는 방법이 명확하지 않다.
우리의 방법은 locally-weighted logistic regression, radial basis SVM, Gaussian Mixture Model과 같은 고전적인 반모수 방법으로 시작하여 multi modal 문제를 처리하기 위해 기계 학습 응용 프로그램에서 풍부한 역사를 가지고 있는 미리 정의된 앵커의 개념에 크게 영향을 받는다. 컴퓨터 비전에서는 탐지(detection)와 인간 자세 추정에 효과적으로 사용되었다. 우리와 마찬가지로 이러한 효과적인 접근 방식은 앵커의 가능성을 예측하고 이러한 앵커(예: 박스 코너, 조인트 위치 또는 차량 위치)에 조건이 지정된 상태의 지속적인 개선을 예측한다.
Method
관측 값 x가 scene안의 모든 agent의 past trajectory와 contextual information(e.g : lane semantics, traffic light states)의 형태로 주어지면, Multipath는 future trajectory “s: p(s)”에 대한 매개변수 분포인 (1)번 식을 제공하고 (2)번 식은 이 분포를 잘 요약하는 명시적 trajectory의 compact weighted set이다.
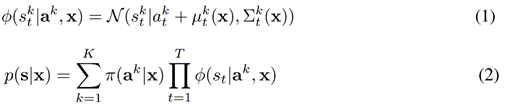
위 식에서 \(s_t\)는 시간 \(t\)에서 에이전트의 상태이고 미래 궤적 \(\bold{s} = [s_1, …, s_T]\)는 \(t=1\)에서 \(T\)까지의 일련의 상태이다. 또한 trajectory에 있는 상태를 웨이 포인트라고도 한다.
본 논문에서는 불확실성의 개념을 독립적인 양으로 분해한다. 의도 불확실성(Intent uncertainty)은 agent의 잠재적인, 대략적인 의도 또는 원하는 목표에 대한 불확실성을 모델링한다. 예를 들어 운전 상황에서 agent가 도달하려는 차선에 대한 불확실성이다. 의도가 정해져도 agent가 의도를 충족시키기 위해 따르는 상태 시퀸스에 대한 불확실성을 설명하는 제어 불확실성이 여전히 존재한다. 의도 및 제어 불확실성은 모두 정적 및 동적 세계 컨텍스트 x의 과거 관찰에 의존한다.
본 논문에서는 의도 집합을 K 앵커 집합 궤적 \(A = {a^k}_{k=1}^K\) 모델링 한다. 여기서 각 앵커 궤적은 일련의 상태이다($$a^k = a_1^k, …, img] à 현재 주어진 것으로 가정). 우리는 소프트 맥스 분포를 사용하여 이 이산 의도 집합에 대한 불확실 성을 모델링한다.
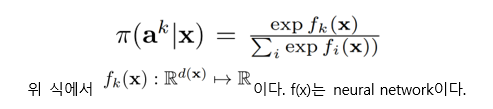
본 논문에서는 불확실성이 intent에 따라 unimodal이라 가정하고 앵커 궤적의 각 웨이 포인트 상태에 따라 제어 불확실성을 가우시안 분포로 모델링한다.
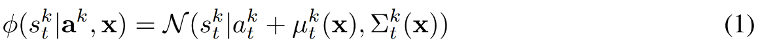
가우시안 파라미터인 \(\mu_t^k\) alc \(\sum_t^k\)는 각 앵커 궤적 \(a_t^k\)의 각 시간단계에 대한 x의 함수로 모델에 의해 직접 예측된다. 가우스 분포 평균 \(a_t^k + \mu_t^k\)에서 \(\mu_t^k\)는 앵커 상태 \(a_t^k\)로 부터의 장면 별 오프셋을 나타낸다. 이전 앵커 분포 위에 장면별 잔차 또는 오류항을 모델링하는 것으로 생각 할 수 있다. 이를 통해 모델은 (특정 도로 형상, 신호등 상태, 다른 에이전트와의 상호작용 등)에서 오는 variation을 이용하여 정적 앵커 궤적을 현재의 context로 구체화할 수 있다.
| Time-step distribution은 앵커가 주어지면 조건부로 독립적이라고 가정한다. 즉 $$\phi(s_t | ·, s_{1:t-1})\(대신\)\phi(s_t | ·)$$를 쓴다. 이 모델링 가정을 통해 단일 추론 패스로 모든 time-step을 공동으로 예측할 수 있으므로 모델을 학습하기 쉽고 효율적으로 평가할 수 있다. 원하는 경우 RNN을 사용하여 조건부 next-time-step 종속성을 모델에 추가하는 것이 좋다. |
전체 상태 공간에 대한 분포를 얻기 위해 agent의 의도에 대해 알아보자.
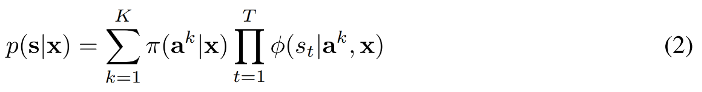
이렇게 하면 모든 시간 단계에 걸쳐 mixed weights가 고정된 가우시안 mixture model distribution이 생성된다. 이것은 2가지 유형의 불확실성을 모두 모델링할 수 있다. 풍부한 표현력, 폐쇄형 분할 함수를 가지고 있으며 컴팩트하다. 확률적 점유 그리드(probabilistic occupancy grid)를 얻기 위해 이 분포를 이산적으로 샘플링된 그리드에서 평가하기가 쉽고, 기본 점유 그리드 공식보다 더 적은 매개 변수로 더 저렴하다.
Obtaining anchor trajectories
우리의 분포는 앵커 궤적 A에 의하여 매개변수화 된다. [6,5]의 논문에서 언급되었듯이 mixture를 직접 학습하는 것은 mode collapse문제를 겪는다. Object detection 및 human pose estimation과 같은 다른 domain에서 일반적인 관행과 마찬가지로 나머지 매개변수를 학습하기 위해 앵커를 수정하기 전에 먼저 앵커를 추정한다. 실제로 k-means 알고리즘을 간단한 근사치로 사용하여 궤적 사이의 following squared distance를 갖는 A를 구했다. \(d(u,v) = \sum_t^T ||M_uu_t - M_vv_t||_2^2\), 여기서 \(M_u, M_v\)는 궤적을 canonical rotation 및 translation-invariant 에이전트 중심 좌표 프레임에 넣는 아핀 변환 행렬 이다. In Sec4에서 일부 데이터 세트에서 k-mean은 몇가지 공통 모드로 심하게 치우친 사전 분포로 인해 고도로 중복된 클러스터로 이어진다. 이를 해결하기 위해 궤적 공간을 균일하게 샘플링하여 A를 얻는 더 간단한 접근 방식을 사용한다.
| Learning. 기록된 주행 궤적의 log-likelihood를 최대화하기 위해 매개변수를 피팅하여 imitation learning을 통해 모델을 훈련한다. 데이터를 \((x^m, \hat{s}^m)_{m=1}^M\)의 형식으로 한다. 방정식 2를 기반으로 다음과 같은 음의 log-likelihood도 loss를 사용하여 가중치 θ로 매개변수화 된 심층 신경망의 출력으로 분포 매개변수 $$\pi (a^k | x), \mu(x)_t^k\(및\)\sum_t^k(x)$$를 예측하는 방법을 배운다. |
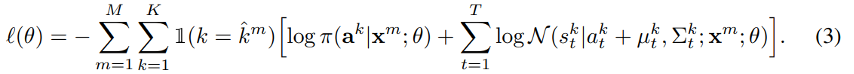
이것은 표준 GMM likelihood 피팅의 time-sequence 확장입니다 [5]. 여기서 \(k^m\)은 state-sequence 공간에서 2-norm distance로 측정된 ground truth 궤적 \(s^m\)에 가장 근접하게 일치하는 앵커의 인덱스이다. 이러한 ground truth 앵커의 hard-assignment는 직접 GMM likelihood 피팅의 난해성을 회피하고 expectation-maximization 절차에 의존하는 것을 피하며 그들이 원하는 대로 앵커 설계를 제 할 수 있도록 한다. 앵커에 soft-assignment(예: ground truth 궤도에 대한 앵커의 거리에 비례)를 쉽게 사용할 수도 있다.
Inferring a diverse weighted set of test-time trajectories.
본 논문의 모델을 사용하면 test time에 표준 샘플링 기술을 피하고 추가 계산 없이 K궤적의 weighted set을 얻을 수 있다: 각 K 앵커 모드에서 MAP 궤적 추정값을 취하고 앵커 \(\pi(a_k | x)\)에 대한 분포를 샘플 가중치(즉 중요도 샘플링, 현재의 path가 선택될 확률)로 고려한다. Metric 및 applications에서 평가를 위해 상위 κ < K 궤적 세트를 요구할 때 이러한 샘플 가중치에 따라 상위 κ를 반환한다.
Input representation.
우리는 다른 recent approaches를 따르고 동적 및 정적 장면 컨텍스트의 history를 top-down 직교 관점에서 렌더링 된 데이터의 3차원 배열로 나타낸다. 처음 두 차원은 하향식 이미지의 공간 위치를 나타낸다. 깊이 차원의 채널은 고정된 수의 이전 time-step의 정적 및 시간에 따라 변하는 (동적) content를 보유한다. Agent의 관찰은 각 time-step에 대해 하나의 채널인 방향 경계 상자 이진 이미지로 렌더링 된다. 신호등 상태 및 도로의 정적 컨텍스트(차선 연결 및 유형, 정지선, 속도 제한 등)와 같은 기타 동적 컨텍스트는 추가 채널을 형성한다. 입력 내용이 dataset마다 다르므로 자세한 내용은 section 4를 참조하자. 이러한 top-down representation을 사용할 때의 중요한 이점은 agent간의 공간 관계 및 의미론적 도로 정보와 같은 상황 정보를 간단하게 표현할 수 있다는 것이다. B.4 섹션에서 행동 예측에 대한 이점을 경험적으로 강조한다.
Neural network details.
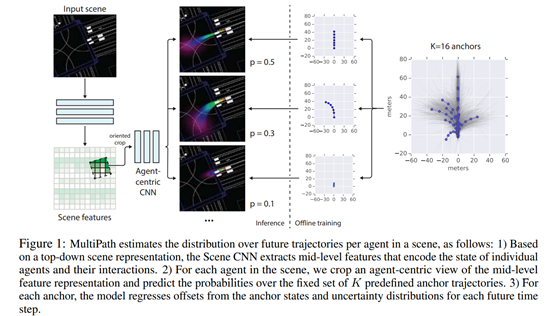
그림 1에서 보았듯이 우리는 먼저 전체 장면에 대한 특징 표현을 추출한 후 장면의 각 agent에 참여하여 agent 별 궤적 예측을 수행하는 jointly-train된 two-stage architecture를 설계하였다.
첫번째 단계는 공간 구조를 보존하기 위한 fully convolution이다. 위에서 설명한 3D input representation을 사용하여 전체 top-down 장면의 3D feature map을 출력한다. 이 scene-level feature extractor에 ResNet 기반 아키텍처를 사용하도록 선택한다. 우리는 모든 실험에 대해 depth별 thinned-out network를 사용하고 dataset에 따라 서로 다른 수의 residual layer를 사용한다. ResNet 설정에 대한 speed-accuracy분석은 B.2 섹션을 참조하자.
| 두번째 단계에서는 이 feature map에서 agent의 위치를 중심으로 11*11크기의 패치를 추출한다. 방향을 변화시키지 않기 위해 추출된 feature는 차별화 가능한 bilinear warping을 통해 agent-centric 좌표계로 회전된다. (이러한 유형의 heading-normalization의 효과는 B.3을 참조하자.) 그런 다음 두번째 agent-centric 네트워크는 agent별로 작동한다. 커널 크기가 3이고 깊이 채널이 8또는 16인 4개의 convolution layer가 있다. 앵커와 time-step 당 이변량 Gaussian을 설명하는 K x T x 5개의 매개변수와 π (a | x)를 나타내는 K 소프트 맥스 로짓을 생성한다. ($µ_x, µ_y, log σ_x, log σ_y, ρ$로 매개 변수화 됨; 마지막 3 개 매개 변수는 에이전트 중심 x,y-coordinate space에서 2 × 2 공분산 행렬 \(\sum_{xy}\)를 정의한다.) |
Experiments
이번 섹션은 이전 prediction task들의 경험적 결과를 제공할 것이다. 우리는 다음의 방법들을 이용하여 Multipah의 다른 측면과 대조를 해볼 것이다.
Multipath
다중 엥커, 모델링 오프셋 μ및 control uncertainty 공분산 ∑가 있는 방법. 일부 실험의 경우 ∑고정을 유지하여 maximum likelihood loss를 단순한 2-loss로 simpify한다. 그러나 ∑가 없으면 더 이상 가능성 p(s|x)를 추정할 수 없으며 오직 distance-based metric만 유효하게 된다.
Regression
Multiple intent 모델링이 중요하다는 가설을 확인하기 위하여 단일 출력 궤적을 regression 하도록 multipath 아키텍처를 수정해 보았다. 이는 [1]의 출력과 유사하나 불확실성을 포함하도록 확장되었다.
Min-of-K
이는 사전 정의된 앵커 없이 K를 예측한다. 저자는 ground truth trajectory까지의 최소 거리로 단일 trajectory에서 2-loss를 정의한다. 이는 Multipath와 유사하나 훈련이 진행됨에 따라 implicit 앵커와 이 앵커를 ground truth로 hard-assignment하게 된다. 이러한 representation은 고유한 ambiguity problems가 존재하며 mode collapse를 유발할 수 있다. 아래 실험에서 이 방법을 확장하여 각 waypoint에서 µ, Σ값을 예측하여 likelihood를 평가한다.
CVAE
Conditional variational Auto-Encoder는 표준 implicit generative sampling model이며 [3]에서 자율 주행의 궤적을 예측하는데 성공적으로 적용되었다. 우리는 Multipath의 앵커 당 MAP trajectory와 비교하여 다양한 샘플 세트를 생성하는 기능을 비교하는데 관심을 두고 있다. MultiPath가 choice of anchor로 인하여 더 나은 적용 범위를 가질 것이라 가정한다. 이 baseline의 경우 second-step의 agent-centric feature추출기 끝에 CVAE를 추가한다. 디코더와 인코더는 동일한 아케텍처를 가지고 있다. 각각 32개 단위로 구성된 4개의 fully connected layer이다.
Linear
past state에 대한 선형 모델을 사용하여 단순한 등속 모델이 얼마나 성능이 나올지 확인한다. 과거에 관찰된 위치를 시간의 선형 함수로 fitting한다(\(x_t = [α_t + β, γ_t + δ]\) for t ≤ 0). 그리고 이 모델을 사용하여 미래의 위치를 나타낸다(\(x_1, … , x_T\)). 우리는 더 안좋은 결과에 대하여 고차 다항식을 사용하여 조사하였다.
공정한 비교를 위해 동일한 input representation과 비교 가능한 모델 아키텍처를 사용하여 single-trajectory regression, Min-of-K 및 CVAE를 구현하였다. Benchmark dataset의 경우 최근 발행된 논문에서 가져온 수치도 보고한다.
Metrics
다른 approaches들은 다양한 output representation을 사용한다. 대표적인 예로 single trajectory prediction[1]과 unweighted set of trajectory samples[3], distribution over trajectories(Our), probabilistic occupancy grids[11] 등이 있다. 각 representation은 각각은 고유한 metrics와 함께 제공되므로 모든 방법을 비교하기는 힘들다. 따라서 우리는 \(\hat{s} = \hat{s}_{t=1...T}\)를 ground truth trajectory라 할 때 다음 metric을 따르도록 하였다.
Log-likelihood(LL)
모든 파라미터를 학습 후에 Multipath가 수행하는 것처럼 모델이 likelihood 평가를 허용하면 \(log p(\hat{s}|x)\)를 사용한다(식 2참조). 이 때 metric은 2xT의 비율로 축소된다. 여기서 T는 time-step이고 2는 2개의 차원을 나타낸다.
Distance-based
이는 ADE(average displacement error)에서 주로 사용하는 \({1 \over T}\sum_{t=1}^T ||\hat{s}_t - \hat{s}^*_t||_2\)와 FDE(final displacement error)에서 주로 사용하는 \(||\hat{s}_T - \hat{s}^*_T||_2\)이다. 이 때 \(s^*\)는 most-likely within weighted set이다.
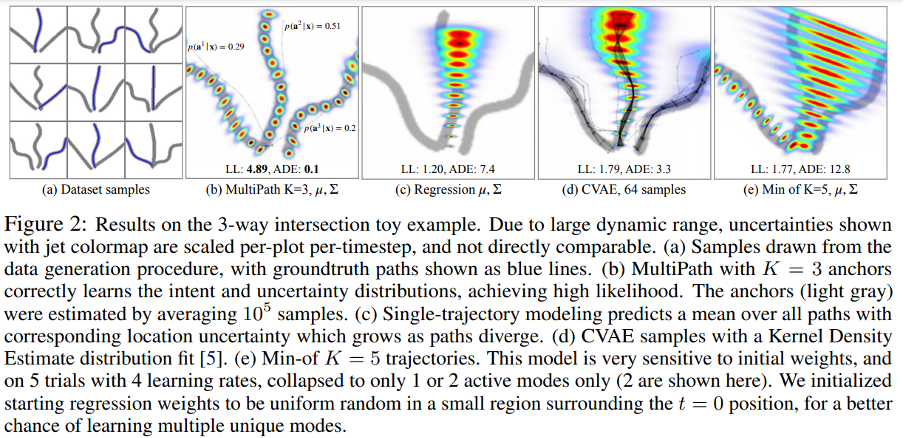
Toy experiment: 3-way intersection
먼저 모델링 가정을 기반으로 생성된 간단한 개념-증명 데이터 집합을 탐색한다. 우리는 intent uncertainty distribution이(0.3, 0.5, 0.2)가 되도록 왼쪽, 중간, 오른쪽 경로를 선험적으로 설정하는 확률로 synthetic 3-way 교차로를 생성한다. Single-trajectory control uncertainty modeling의 유연성을 강조하기 위하여 각 경로는 매개변수화 된 sin wave(\(y=sin(\omega t+\phi)\))를 샘플링 하여 생성된다. 여기서 주파수는 ω~ U(0,2)이고 phase shift는 φ ∼ U(-π, , π)로 잡는다. figure 2처럼 다른 방법에 비하여 Multipath는 기본 분포를 올바르게 맞추고 intent uncertainty를 복구하며 거의 Bayes-optimal likelihood에 도달할 수 있었다.
4.3 Behavior prediction for autonomous driving
제안된 시스템의 성능을 확인하기 위하여 북미의 여러 도시에서 실제 운전 장면의 대규모 데이터 세트를 수집하였다. 데이터는 카메라, 라이더 및 레이더가 장착된 차량으로 캡처 되었다. [2, 6]에서와 같이 업계 수준의 인식 시스템이 차량, 보행자 및 자전거 타는 사람을 포함한 모든 근처 에이전트에 대해 충분히 정확한 포즈와 트랙을 제공한다고 가정한다. 실험에서 우리는 감지 차량을 장면의 다른 에이전트와 구별할 수 없는 추가 에이전트로 취급한다. 수집된 차량 trajectory의 대부분은 고정되어 있거나 일정한 속도로 똑바로 이동한다. 두 경우 모두 행동 예측 관점에서 특히 흥미롭지는 않다. 이 문제와 기타 데이터 세트 왜곡을 해결하기 위하여 일정한 곡률과 거리에 대해 균일한 2D grid를 통하여 future trajectory의 공간을 분할하고 각 분할의 예제 수가 최대 5%로 제한되도록 계층화된 샘플링을 수행하였다. 결과 데이터 세트. 균형 잡힌 데이터 센트는 총 385만개의 예제, 575만 개의 agent trajectory를 포함하여 약 200시간의 운전을 구성한다.
이 data에 대한 top-down rendered input 텐서는 400px*400px의 해상도를 가지며 실제 좌표에서 80m * 80m에 해당한다. 0.2초(5Hz)마다 time step을 샘플링 한다. 다음 feature가 깊이 차원에 쌓여 있다
- 색으로 구분된 도로의 semantics가 3-channels
- 도로간 거리지도가 1-channel
- 속도 제한에 대한 1-channel
- 지난 5초 동안의 신호등 상태에 대한 5-channel
- 5개의 시간 단계에 각각에 대한 차량의 top-down orthographic projection에 관한 5개의 채널).
이러한 결과 총 15개의 채널이 생긴다. 향후 30개의 프레임(6초)의 trajectory를 예측한다. 앵커 수 K는 multipath µ, Σ의 경우 16이고 multipath µ의 경우 64로 결정된다. Scene-level 네트워크는 25%의 depth multiplier인 ResNet50이며 ResNet에서 손실된 공간 해상도의 일부를 다시 200*200으로 복원하는 depth-to-space작업이 이어진다. 마지막으로 우리는 learning rate warm-up 단계 및 cosine learning rate decay를 사용하여 batch size 32에서 500k step에 대한 end-to-end modeling을 한다.
실험 결과는 표1에 표시된다. Multipath는 모든 metric에서 baseline을 능가하는 성능을 보였다. Log-likelihood와 관련하여 이 작업에 대한 most log-likelihood 측정 값이 3~4.2 nats 사이로 떨어지는 것을 관찰하였으므로 regression baseline과 비교하여 Multipath에서 약 0.2 nat의 이득이 상당히 중요하다. 이러한 결과에 대한 심층 분석은 섹션 A를 참조하자. Multipath µ, Σ에는 16 개의 앵커가 사용되었으며 MultiPath µ에는 64 개가 가장 좋은 K이다. 앵커 수 K의 효과에 대한 분석은 섹션 B.1을 참조하자. 그리고 앵커의 시각화는 섹션 C를 참조하자.


4.4 Stanford Drone
Stanford Drone dataset은 top-down view로 되어있는 데이터 집합이다. 이는 orthographic에 가깝다고 볼 수 있다. 여기에는 보행자, 자전거 타는 사람, 차량등이 포함되어 있다. 이 RGB 이미지는 주행중인 차량에서 렌더링 된 road semantics와 유사하고 볼 수 있다. 여기서 우리는 2초 동안의 사진(5 프레임)을 사용하여 향후 4.8초(12 프레임)을 예측한다. 추가적인 정보는 Sec D를 참조하자.
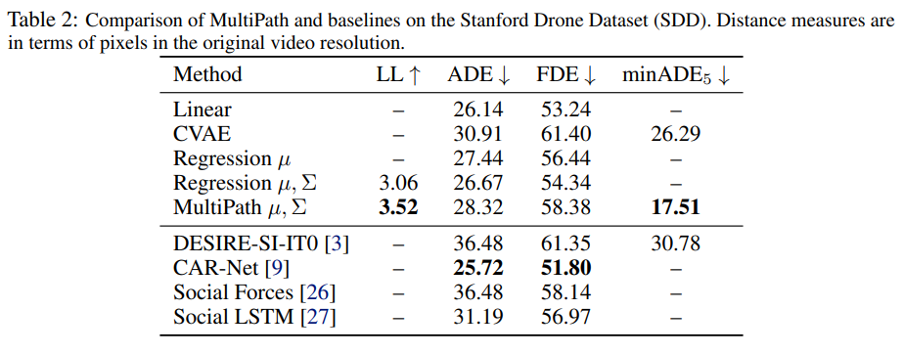
Table 2에서 보듯이 본 논문의 모델은 SOTA를 찍었다. 그런데 여기서 CAR-Net은 우리의 single-trajectory model과 비견된다. 그들의 방법은 최고의 single trajectory distance metric 성능을 얻기 위해 sophisticated attention 및 sequential architecture에 초점을 맞추고 있다. 흥미롭게도 우리의 single trajectory model은 불확실성을 예측하도록 훈련되었을 때 더 잘 수행되며 이는 [8]에서 논의된 불확실성 모델링의 잠재적인 이점이다.
4.5 CARLA
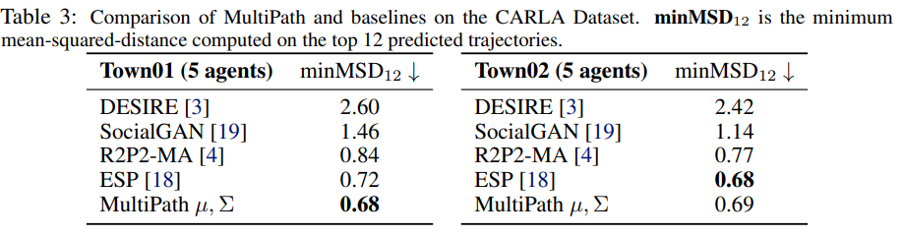
CARLA simulator를 사용하여 생성된 사용 가능한 multi-agent trajectory forecasting 및 planning dataset에서 multipath를 평가해 보았다. 세부사항은 Sec E를 참조하자. Table 3은 각각의 다른 방법에 대해 [18]에서 보고한 결과를 재현하고 multipath의 성능을 이들과 비교한다. 평가 결과를 보고하기 위해 [18]에 정의된 대로 상위 k=12개의 prediction으로 minMSD metirc을 나열한 것이다.
5. Conclusion
실제 설정에서 agent에 대한 future trajectory의 매개 변수 분포를 예측하는 모델인 multipath를 도입하였다. Synthetic 및 real data set을 통해 Multipath가 이전까지의 single-trajectory model 및 stochastic model에 비하여 성능도 좋고 단 1개의 feed-forward inference pass만 필요하다는 점에서 다른 모델보다 좋다는 것을 보였다.