TFRecord 사용법
TFRecord의 간단한 사용법에 대해 서술한 포스팅입니다.
TFRecord란
TFRecord는 텐서 플로우에서 학습을 위한 데이터를 저장하는 포멧중 하나이다. TFRecord는 여러개의 파일들을 하나의 바이너리 포맷 파일로 저장한다. 이에 따라 학습시 데이터 데이터를 빠르게 읽어올 수 있게 된다.
TFRecord 파일 작성법
한번 TFRecord파일을 작성해 보겠습니다.
저는 Voc dataset으로 작성을 시도하였습니다.
우선 필요한 라이브러리를 import 해옵니다.
from xml.etree.ElementTree import parse
import tensorflow as tf
from PIL import Image
from glob import glob
그 후 VOC dataset의 레이블을 우선 dictionary형태로 저장해둡니다.
labels = {"person": 0, "car": 1, "bicycle": 2, "bus": 3, "motorbike": 4, "train": 5, "aeroplane": 6, "chair": 7, "bottle": 8, "diningtable": 9, "pottedplant": 10, "tvmonitor": 11, "sofa": 12, "bird": 13, "cat": 14, "cow": 15, "dog": 16, "horse": 17, "sheep": 18, "boat": 19}
그다음 tfrecord의 data형식을 지정해줍니다.
저는 VOC dataset중 bounding box, label, image의 3가지 데이터를 받아올 것입니다.
bounding box는 float형식으로, label은 int형식으로, 이미지는 byte형식으로 받아올것 입니다.
따라서 아래와 같이 선언해줍니다.
def float_list_feature(value):
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def int64_list_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
이 때 저는 bounding box를 아래와 같이 (n,4) 형식으로 선언하지는 않았습니다.
[[xmin, ymin, xmax, ymax],
[xmin, ymin, xmax, ymax],
[xmin, ymin, xmax, ymax],
... ]
대신 아래와 같이 (n*4) 형식으로 선언하였습니다
[xmin, ymin, xmax, ymax, xmin, ymin, xmax, ymax, xmin, ymin, xmax, ymax ...]
이제 전처리는 끝났습니다. 이제 데이터를 저장하면 됩니다. 이때 유의하실 tf.train.Example 부분입니다.
내가 어떠한 데이터를 어떠한 이름으로, 그리고 어떠한 데이터 형식으로 저장해 놓았는지를 기억해 놓으셔야 나중에 불러오기 편하실겁니다.
def write_tfrecord(file_path, writer):
xml_files = glob(file_path + "/Annotations" + "/*.xml")
for file in xml_files:
# xml 파일로부터 데이터 불러오기
tree = parse(file)
root = tree.getroot()
img_name = root.findtext("filename")
img = open(file_path + "JPEGImages/" + img_name,'rb').read()
ob = root.findall("object")
bbox = []
label = []
for x in ob:
bbox.append(float(x.find("bndbox").findtext("xmin")))
bbox.append(float(x.find("bndbox").findtext("ymin")))
bbox.append(float(x.find("bndbox").findtext("xmax")))
bbox.append(float(x.find("bndbox").findtext("ymax")))
label.append(int(labels[x.findtext("name")]))
# 불러온 파일을 tfrecord형식으로 저장
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/bbox': float_list_feature(bbox),
'image/label': int64_list_feature(label),
'image/encoded': bytes_feature(img),
'image/name': bytes_feature(img_name.encode('utf-8'))
}))
writer.write(tf_example.SerializeToString())
tfrecord_filename = 'Voc.tfrecord'
writer = tf.io.TFRecordWriter(tfrecord_filename)
datasets = write_tfrecord("VOCdevkit/VOC2012/", writer)
그러면 현재 경로에 “voc.tfrecord”가 생겼을 겁니다.
TFRecord 파일 불러오기
이번에는 tfrecord 파일을 불러와 보겠습니다.
우선 tfrecord에서는 위에서 제가 tfrecord파일의 데이터들을 어떠한 이름으로 그리고 어떠한 형식으로 저장했는지가 필요합니다.
저는 image를 “image/encoded”라는 이름으로 bytes형식으로 저장했습니다.
label은 “image/label”이라는 이름으로 int_list형식으로 저장했습니다.
bbox는 ‘image/bbox’라는 이름으로 float_list형식으로 저장했습니다.
파일 이름은 ‘image/name’이라는 이름으로 bytes형식으로 저장했습니다.
따라서 다음과 같이 코드를 사용하시면 됩니다.
def load_tfrecord(filenames):
raw_dataset = tf.data.TFRecordDataset(filenames)
for d in raw_dataset:
example = tf.train.Example()
example.ParseFromString(d.numpy())
img = tf.io.decode_image(
contents = example.features.feature['image/encoded'].bytes_list.value[0],
channels=3,
dtype=tf.dtypes.uint8
)
image_name = example.features.feature['image/name'].bytes_list.value
label = example.features.feature['image/label'].int64_list.value
bbox = example.features.feature['image/bbox'].float_list.value
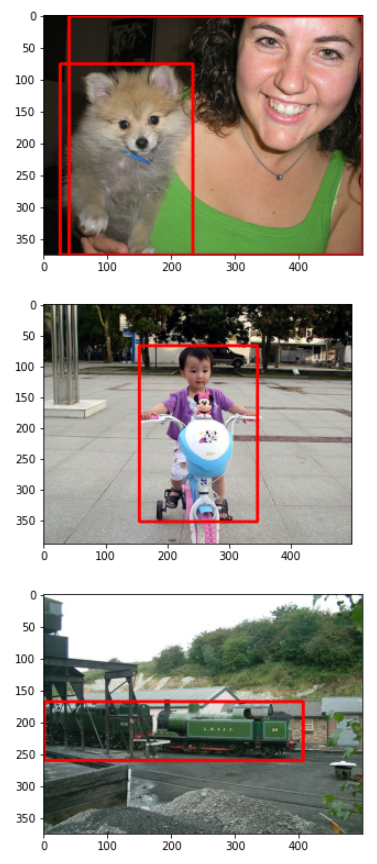
그렇다면 이번에는 제대로 불러와졌는지 테스트를 해보겠습니다. 이 때는 모든 데이터를 사용하지는 않고 4개의 data만 사용하겠습니다. 그러기 위해 raw_dataset.take(4)를 사용했습니다.
import cv2
import numpy as np
from matplotlib import pyplot as plt
def load_tfrecord(filenames):
raw_dataset = tf.data.TFRecordDataset(filenames)
raw_dataset = raw_dataset.take(4)
color = (255, 0, 0) # color는 blue로 지정
for d in raw_dataset:
example = tf.train.Example()
example.ParseFromString(d.numpy())
img = tf.io.decode_image(
contents = example.features.feature['image/encoded'].bytes_list.value[0],
channels=3,
dtype=tf.dtypes.uint8
)
image_name = example.features.feature['image/name'].bytes_list.value
label = example.features.feature['image/label'].int64_list.value
bbox = example.features.feature['image/bbox'].float_list.value
img = np.frombuffer(img, np.uint8).reshape(img.shape)
for i in range(0, len(bbox), 4):
img = cv2.rectangle(img, (int(bbox[i]),int(bbox[i+1])), (int(bbox[i+2]),int(bbox[i+3])), blue_color, 3)
plt.imshow(img)
plt.show()
load_tfrecord("Voc.tfrecord")