Distillation for High-Quality Knowledge Extraction via Explainable Oracle Approach
Knowledge Distillation이란
Knowledge distillation은 대규모 모델의 지식을 작은 모델로 압축하는 기법이다. Knowledge distillation의 목적은 규모가 큰 모델(Teacher model)로 부터 추출된 지식(knowledge)을 더 작은 모델(Student model)로 전달하여, Student model이 Teacher model과 유사한 성능을 발휘하도록 하는것이다.
Knowledge distillation의 과정에서 여러 유형의 지식이 전달될 수 있는데, 이를 response knowledge와 feature knowledge로 구분할 수 있습니다:
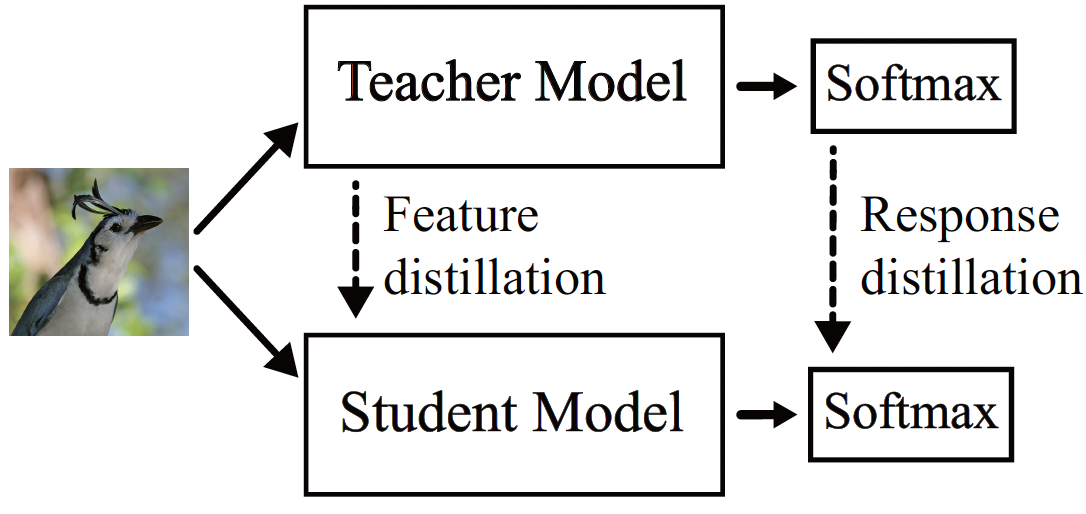
1. Response Knowledge:
Response knowledge는 Teacher model의 최종 출력(응답)을 기반으로 한 지식입니다. 즉, Teacher model의 분류 문제에서 각 클래스에 대한 softmax 확률을 Student model에게 제공하여, Student model이 이를 학습하도록 하는것이다. 이러한 확률 값은 단순한 정답 레이블보다 Teacher model의 confidence나 경향을 포함한 더 풍부한 정보를 포함하고 있기 때문에 Student model이 더욱 효율적으로 학습할 수 있다. 이를 통해 Student model이 Teacher model이 예측한 클래스 간의 미묘한 차이를 이해하게 되어, 학습 과정에서 고품질의 지식을 효과적으로 학습할 수 있다.
2. Feature Knowledge:
Feature knowledge는 중간 레이어에서 추출된 피처(특징 맵)을 기반으로 한 지식이다. Teacher model의 중간 레이어에서 학습된 중요한 특징들이 Student model로 전달되어, Student model이 이 특징들을 학습할 수 있게 한다. Feature knowledge는 Teacher model이 입력 데이터에서 중요한 패턴을 포착하는 방법을 Student model이 배우는 데 도움을 준다. 이 방법은 모델의 구조적 차이에도 적용 가능하여, Teacher와 Student model의 아키텍처가 다르더라도 유효하게 동작할 수 있다.
Student Model의 성공적인 학습을 위한 Teacher Model의 역할
이 때 student model을 잘 학습시키기 위해서는 teacher model은 아래와 같은 역할을 준수해야 한다.
높은 성능의 모델 유지: Teacher model은 기본적으로 높은 정확도와 성능을 유지해야 한다. Teacher model의 성능이 낮다면, Student model도 잘못된 패턴을 학습하게 될 가능성이 크다. 이를 위해 Teacher model은 충분한 데이터와 적절한 학습 전략으로 사전 학습이 되어 있어야 하며, 다양한 데이터 분포와 상황에서 좋은 성능을 발휘할 수 있어야 한다.
고품질의 Knowledge 제공: Teacher model은 Student model에 전달할 knowledge의 품질이 높아야 한다. 이 때 knowledge의 품질은
t-SNE,Silhouette Score,ECE(Expected Calibration Error)등을 통하여 평가 될 수 있다.t-SNE: t-SNE는 고차원 데이터(예: feature knowledge)를 2차원 또는 3차원으로 시각화하여, 데이터가 어떻게 군집을 이루고 있는지 시각적으로 확인하는 데 사용된다. 동일한 class, 혹은 유사한 class간에 군집이 잘 형성되어 있을수록 품질이 높다고 평가할 수 있다.
Silhouette Score: Silhouette Score는 clustering 성능을 측정하는 지표로, Teacher model과 Student model이 데이터의 특징을 어떻게 그룹화하는지 평가할 수 있다. 높은 Silhouette Score는 각 군집이 잘 구분되면서도 내부적으로 응집력이 강한 것을 의미하며, 이는 모델이 고품질의 feature knowledge를 학습했음을 나타낸다.
ECE: ECE는 모델이 예측한 확률 값과 실제 정답 간의 일치 정도를 나타냅니다. 잘 학습된 Teacher model은 confidence값과 실제 정답을 맞출 확률이 일치할 가능성이 크다. 즉 잘 calibration 된 model은 더 고품질의(즉, 신뢰할 수 있는) 지식을 제공할 수 있다.
Proposed Method
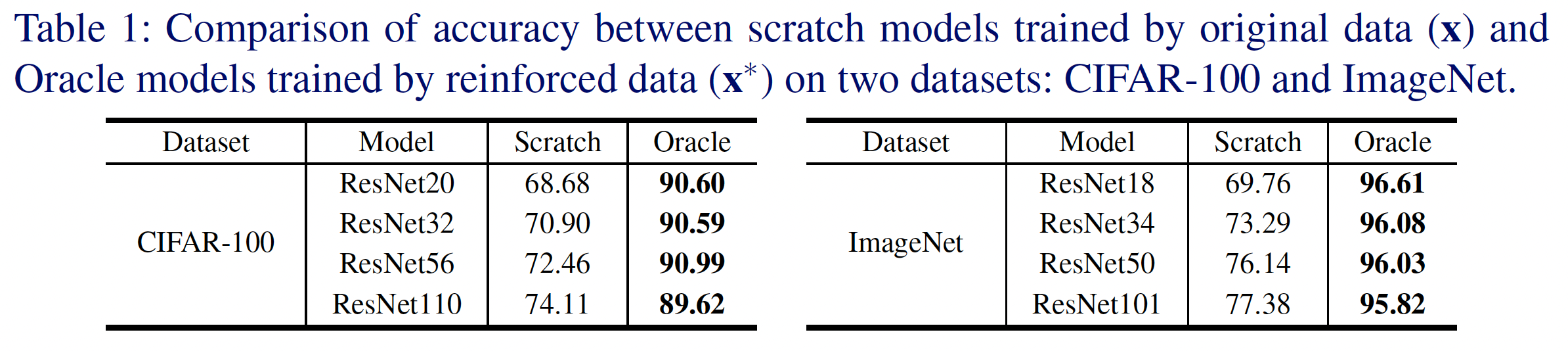
본 논문에서는 성능과 지식의 품질을 동시에 개선할 수 있는 새로운 방법을 제시하며, 이를 위해 reinforced data를 활용한다. Reinforced data는 adversarial example과 반대의 개념으로, 입력 데이터에서 발생한 gradient를 빼는 방식으로 생성된다. 이는 모델의 손실을 최소화하는 방향으로 입력을 수정하는 것이며, 그 결과 아래 표에서 확인할 수 있듯이 모델의 성능이 크게 향상된다.
Reinforced data를 만들고(step A), 이를 이용해 knowledge distillation을 진행하는(step B) 방법은 아래 그림과 같다.
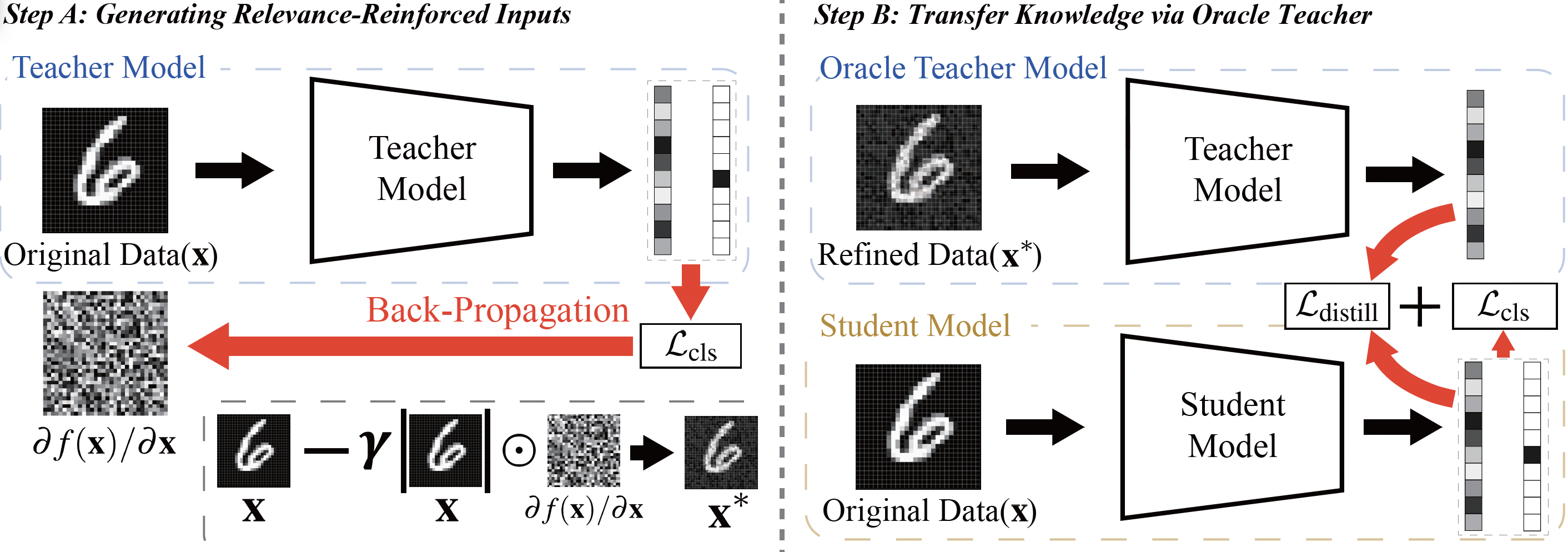
- Step A: Teacher model의 output과 ground truth로부터 생성된 loss를 이용해 back-propagation을 수행하여, input data의 gradient $ \partial f(x)/\partial x $ 를 구한다. 그런 다음 input data의 scale을 반영해주기 위해 gradient와 input data를 element wise로 곱한 후, 가중치 $ \gamma $를 적용해 input data에서 이를 차감한다.
- step B: Reinforced data를 Teacher model에 다시 입력하여 더 높은 정확도를 가진 response knowledge를 생성하고, 이를 Student model과 KL-divergence를 통해 비교하여 distillation loss를 구한다.
Student model은 여기에 일반적인 classification loss $\mathcal{L}_{cls}$를 더해 학습하며, 이렇게 학습된 Student model은 SOTA 수준의 성능을 넘어서게 된다.
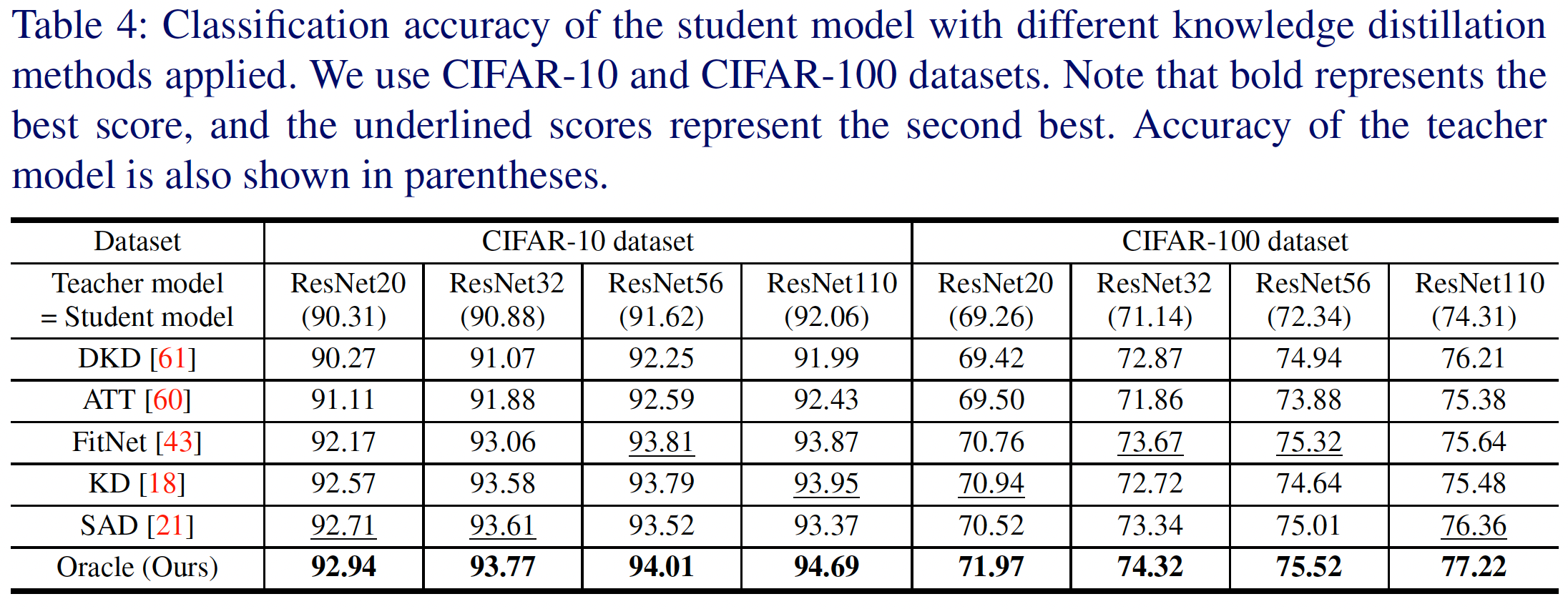
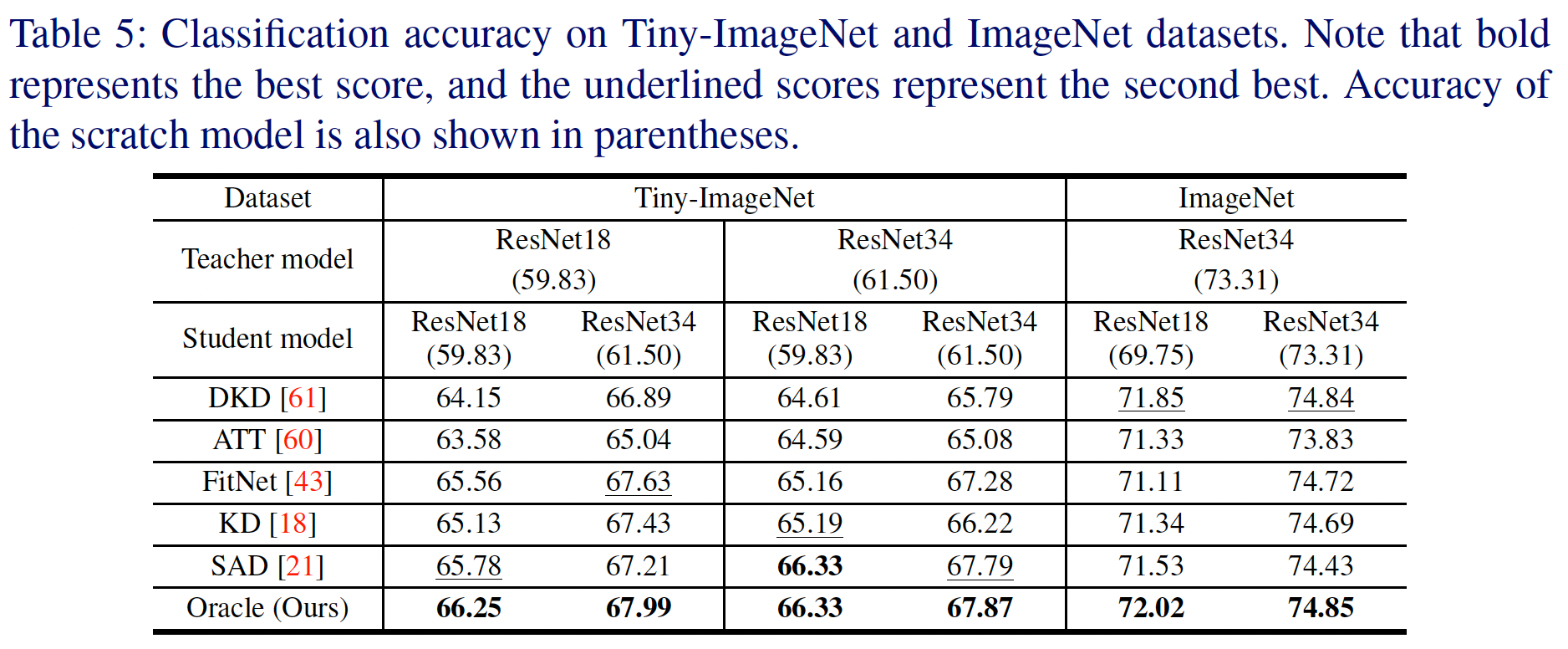
Is the Knowledge Obtained from Our Oracle Teacher Model Good Enough
위에서 우리는 teacher model은 고품질의 knowledge를 추출해야 한다고 서술했다. 본 논문에서는 knowledge의 품질 측정을 위해 t-SNE, Silhouette Score, ECE(Expected Calibration Error)와 같은 지표들을 사용하였다.
ECE
ECE(Expected Calibration Error)는 model의 confidence score 인$conf(\cdot)$와 실제로 맞춘 정답의 비율인 $acc(\cdot)$간의 차이를 수치화한 지표이다. 즉, 모델이 예측에서 80% ~ 85%의 확률을 자신한다면, 실제로도 그 비율만큼 정답을 맞춰야 한다는 것을 의미한다. 이를 정량적으로 평가하기 위해, ECE는 다음과 같은 식으로 정의된다: \[ECE = \sum_{b=1}^{B} \frac{|b|}{N} \left| acc(b) - conf(b) \right|\]
위 식에서 confidence score $conf(b)$와 정확도 acc(b)는 각각 아래와 같이 계산된다:
| $ conf(b) = \frac{1}{ | b | } \sum_{j \in b} p_j $ : bin $b$ 내에서 예측 확률의 평균 |
| $ acc(b) = \frac{1}{ | b | } \sum_{j \in b} \mathbf{1}(p_j = y_j)$: bin $b$내에서 실제 정답을 맞춘 비율. |
이 정의를 통해 ECE는 모델의 예측 신뢰도가 실제 결과와 얼마나 일치하는지를 측정할 수 있다.
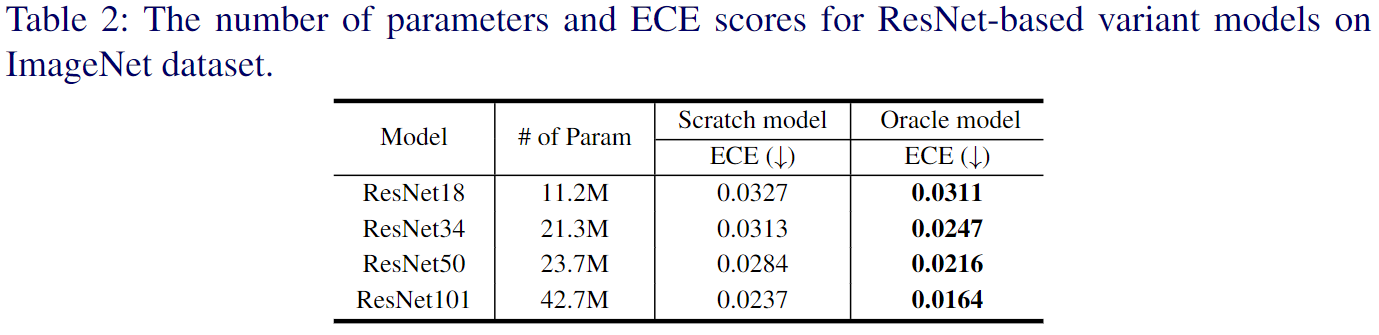
ECE는 단순히 예측의 맞고 틀림을 넘어서, 모델의 예측이 얼마나 신뢰할 수 있는지에 대한 중요한 정보를 제공하며, 이를 통해 teacher model의 response knowledge의 품질을 정량화 할 수 있다.
본 논문에서 제시한 Oracle model은 Scratch model에 비해 더 낮은 ECE 값을 보이는데, 이는 Oracle model이 더 높은 신뢰도를 가지고 있음을 의미한다.
t-SNE
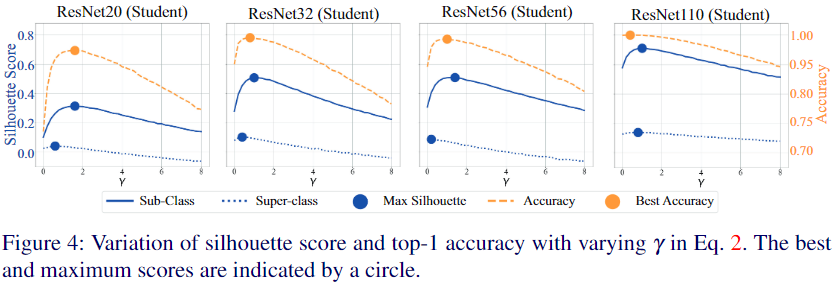
t-SNE(t-distributed Stochastic Neighbor Embedding)은 고차원의 데이터를 저차원의 공간으로 효율적으로 시각화하기 위한 비선형 차원 축소 기법이다. 주로 2차원이나 3차원으로 데이터를 축소하여 시각적으로 표현하는 데 사용되며, 데이터의 클러스터링과 패턴을 식별하는 데 유용하다. 본 논문에서는 response knowledge를 2차원으로 축소하여 평면에 투영하였고 이들간의 거리를 측정하였다. 그 결과 reinforced data를 만드는 식에서 나왔던 $ \gamma$ 값을 키울 수록 군집이 더욱 잘 형성된것을 확인할 수 있다.

Silhouette Score
Silhouette score는 군집이 얼마나 잘 형성되어있는지를 나타내는 지표이다. 이 역시 일정 수준까지는 $\gamma$ 값이 높아짐에 따라 군집이 점점 더 잘 형성되는 것을 확인할 수 있다.
Conclusion
본 논문에서는 gradient-based explainable AI를 활용하여 모델의 성능과 knowledge distillation에서의 압축률을 효과적으로 향상시켰다. 또한, teacher model에서 추출한 response knowledge의 품질을 다양한 방법으로 평가하고, 이를 통해 학습된 student model의 성능이 SOTA 성능을 초과하는 결과를 얻었다.